Process Specific AI for Regulated Firms | Fortay Connect
by
Fortay Connect
|
26th Jun 2026
Posts By Topics
- News (17)
- Unified Communications (17)
- Contact Centre (16)
- AI (15)
- Ring Central (13)
- Zoom (13)
- CX (12)
- Events (12)
- Avaya (7)
- GoToConnect (7)
- Contact Centre Consulting (6)
- Financial Services (6)
- Partners (6)
- Virtual Agent (6)
- Case Studies (5)
- Resources (5)
- Unified Communications Solutions (5)
- AI Meeting Assistant (2)
- AI Sales Analytics (2)
- Chatbot (2)
- Conversational Intelligence (2)
- Employee Communications (2)
- Legal (2)
- Microsoft Teams (2)
- Trends (2)
- Video (2)
- AI Companion (1)
- AI Receptionist (1)
- DialPad (1)
- Neurodiversity (1)
- Omnichannel (1)
- Sentiment Analysis (1)
- workvivo (1)
Process Specific AI for Regulated Firms | Fortay Connect
26 June 2026
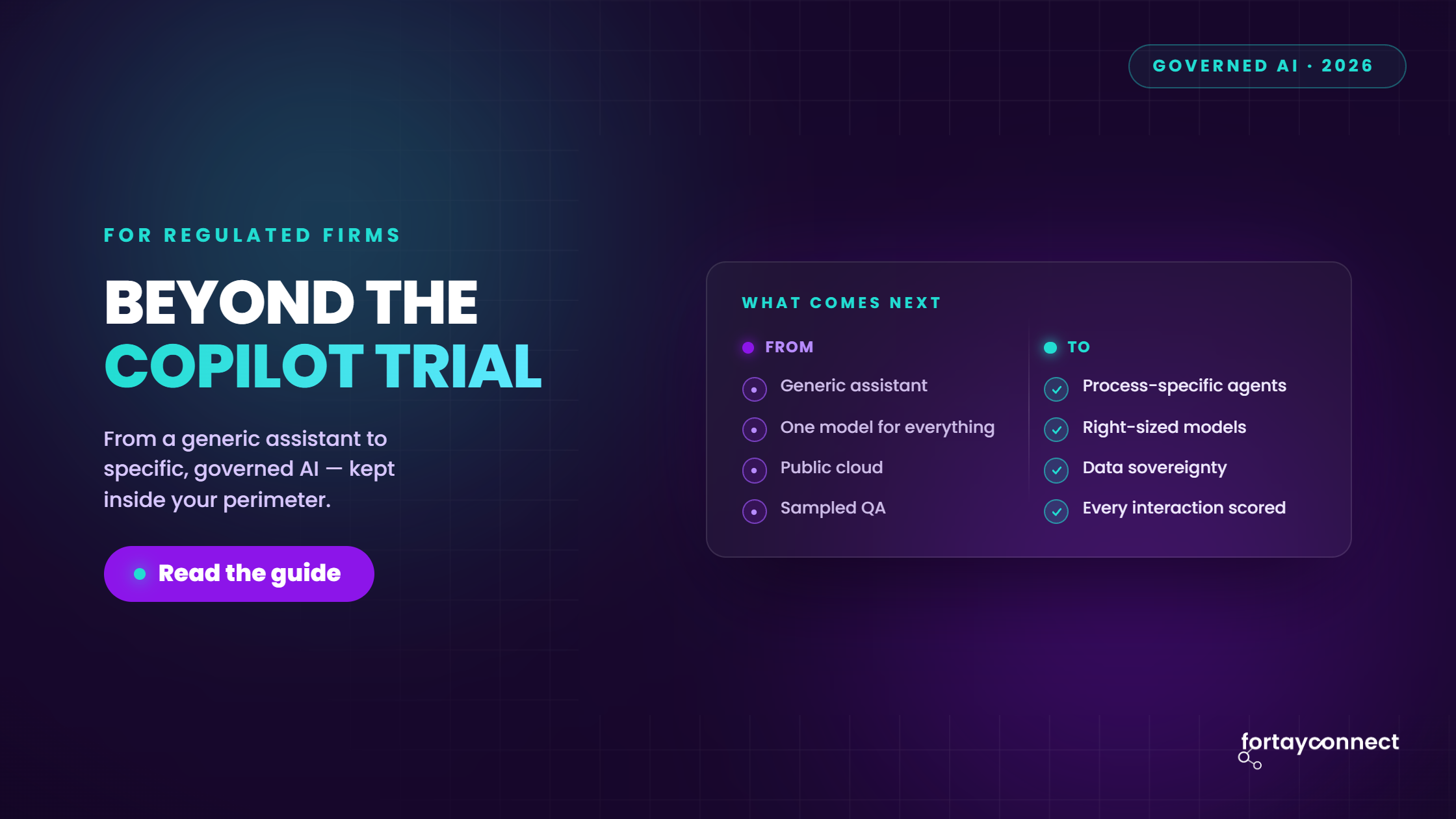
What Comes After the Copilot Trial? A Guide for Regulated Financial Firms
Most regulated financial firms that run a Microsoft 365 Copilot trial reach the same inflection point. Productivity gains in drafting, summarising, and knowledge retrieval are real and measurable. Then the question arrives: what comes next?
The honest answer is not a bigger licence rollout. For firms operating under FCA oversight, PRA rules, or equivalent regulatory frameworks, the next step is a deliberate shift to governed, process-specific AI. That means selecting the right model for a specific bounded workflow, keeping data inside the right perimeter, and extending automation into the back-office processes that generic assistants were never designed to handle.
Three tests determine whether your next AI investment is the right one:
- Governance: Can you explain, audit, and control every decision the model makes within that process?
- Sovereignty: Does the deployment model match your data sensitivity and regulatory posture, from controlled cloud to fully isolated?
- Legacy reach: Can the AI operate across the systems your back office actually runs on, not just the ones with modern APIs?
The rest of this guide works through each of those questions in sequence.
Key takeaways
- The next step after a Copilot trial is not a bigger licence rollout. It is a shift to governed, process-specific AI.
- Back-office workflows are the strongest early target: high volume, stable rules, and clear exception paths.
- Data sovereignty is a design spectrum, not a binary choice. Most regulated firms will operate across more than one tier.
- Legacy systems without APIs are not a barrier. Document AI, OCR, and UI-layer automation can bridge the gap selectively.
Why do Copilot trials plateau in regulated firms?
Copilot is a capable general assistant. It accelerates knowledge work: drafting communications, summarising meetings, searching across document libraries. For many firms, the initial trial cohort reports genuine time savings, and those numbers are credible.
The plateau arrives when firms try to move beyond productivity assistance into the processes that carry real regulatory weight. The Bank of England and FCA's joint AI survey identifies the most commonly cited barriers to AI adoption in UK financial services as data quality and privacy concerns, model explainability, and third-party dependency risk. A broader Copilot rollout tends to intensify all three rather than resolve them.
The gap is structural, not a failure of the product:
|
What Copilot is well-suited to |
Where regulated firms hit the ceiling |
|---|---|
|
Drafting and editing documents |
Processes requiring full audit trails and explainable decisions |
|
Summarising meetings and calls |
Workflows governed by FCA, PRA, or DORA obligations |
|
Searching internal knowledge bases |
Systems with no modern API or integration surface |
|
Accelerating individual knowledge work |
Back-office automation requiring workflow orchestration |
|
General Q&A across connected content |
Processes where data must stay inside a defined perimeter |
The point is not that Copilot is the wrong tool. It is that general assistants are designed for breadth, not depth. The highest-friction regulated processes require the opposite approach: a narrow, deeply governed deployment on a single workflow, with human oversight built in from the start.
What is process-specific AI, and how is it different?
Process-specific AI is not a product category. It is a design philosophy. Build around one bounded workflow, one decision pattern, or one document-heavy task. Not one assistant for everything.
In practice, this usually means combining smaller, fine-tuned models with explicit business rules, defined human checkpoints, and workflow orchestration logic. The objective is not model novelty. It is operational fit, auditability, and measurable outcomes within a controlled boundary.
Four characteristics define a process-specific deployment:
- Bounded scope. The AI operates on a defined input type and produces a defined output. It does not generalise beyond that boundary. This makes it auditable and containable.
- Explicit governance. Every decision path is logged. Human review points are built into the workflow, not bolted on afterwards. The model's reasoning can be inspected and explained.
- Appropriate model size. Smaller, task-tuned models are often more accurate, faster, and cheaper to run on specific workflows than large general-purpose models. They are also easier to govern and host within your own environment.
- Integration with workflow, not just data. The AI is embedded in the actual process, reading inputs, triggering actions, and passing exceptions to human reviewers. It is not a chat interface layered on top.
This approach is gaining traction in regulated sectors precisely because it aligns with how regulators think about accountability: clear ownership, traceable decisions, and human oversight at defined points.
Can AI work with legacy core systems that have no APIs?
This is often the real constraint. Many regulated financial firms operate core banking or insurance platforms that were built decades before modern integration standards existed. They have no REST APIs, no event streams, and no straightforward path to direct integration. Generic AI assistants stop here.
Process-specific AI does not have to.
The key is using the right combination of techniques to bridge the legacy gap without requiring a full re-platforming project. The most practical approaches are:
- Optical and intelligent character recognition (OCR/ICR). AI models can read scanned documents, printed forms, and legacy-format outputs with high accuracy, extracting structured data from sources that have no programmatic interface.
- UI-layer automation. Where a human operator currently navigates a terminal or screen-based system, a supervised automation layer can replicate those interactions, reading outputs and driving inputs without touching the underlying application.
- Document AI for unstructured data. Loan applications, correspondence, claims forms, and compliance documents contain critical information that sits outside structured databases. Document AI extracts, classifies, and routes that information into workflow without manual re-keying.
- Workflow orchestration across systems. Rather than integrating systems directly, orchestration layers co-ordinate actions across them, passing data and triggering steps based on rules and model outputs.
None of this is trivial. Legacy environments vary enormously, and the right approach depends on the specific platform, process volume, and exception profile. The point is that the absence of a modern API is not a reason to stop. It is a reason to be selective about which processes to target first, prioritising those with high volume, stable rules, and clear exception paths.
What does data sovereignty actually look like?
Data sovereignty is frequently invoked in financial services AI conversations and rarely defined with enough precision to be useful. It is not a binary choice between cloud AI and on-premises AI. It is a design spectrum. The right position on that spectrum depends on process sensitivity, your regulatory posture, and your operational resilience requirements.
Sovereignty is not just about where data sits. It is about who can access it, how model interactions are logged, and what third-party exposure exists at inference time.
A practical way to think about the spectrum:
|
Deployment model |
Data location |
Third-party access |
Suitable for |
|---|---|---|---|
|
Vendor-managed cloud with contractual controls |
Provider data centres |
Limited, contractually governed |
Lower-sensitivity productivity workflows |
|
Private cloud (dedicated tenancy) |
Your chosen region |
Minimal, infrastructure-level only |
Regulated back-office processes |
|
On-premises or sovereign cloud |
Your own environment |
None at inference time |
Highly sensitive data, strict regulatory posture |
|
Air-gapped / fully isolated |
Your own environment |
None |
Highest sensitivity, national security-adjacent |
Most regulated financial firms will operate across two or three of these tiers simultaneously, depending on process sensitivity. The risk of treating sovereignty as a single firm-wide policy is that it either over-restricts lower-sensitivity workflows or under-protects the ones that matter most.
The FCA's AI strategy and the Bank of England's supervisory expectations both point in the same direction: accountability for AI decisions sits with the regulated firm, not the vendor. Deployment model choices should reflect that.
Where does AI pay off in the back office?
Back-office financial services workflows share a common profile: high transaction volume, stable rules, significant manual touchpoints, and exception-handling that consumes disproportionate time. That profile is well-suited to process-specific AI, precisely because the boundaries are clear and the value of getting it right is measurable.
The use cases with the strongest combination of volume, error rate, and regulatory sensitivity are:
- Document classification and data extraction. Mortgage applications, KYC packs, claims submissions, and account change requests arrive in mixed formats. AI that classifies, extracts, and validates against rules reduces manual re-keying and accelerates straight-through processing.
- Reconciliation and exception flagging. High-volume transaction matching with automated escalation of unmatched items cuts the time operations teams spend on routine reconciliation while improving audit trail quality.
- Compliance validation on correspondence and disclosures. AI can check outbound documents against policy templates and regulatory requirements before they leave the firm, reducing the risk of non-compliant communications reaching customers.
- Case triage and prioritisation. Incoming queries, complaints, and escalations can be classified by urgency, regulatory obligation, and complexity, ensuring the highest-risk items reach the right reviewer first.
- Quality assurance on agent interactions. Scoring every customer interaction against policy and compliance criteria, rather than sampling a subset, provides a materially different level of oversight. This is covered in more detail in the next section.
For a deeper look at how AI is reshaping the contact centre side of financial services operations, the Fortay Connect CX and contact centre page covers the customer-facing dimension in detail.
How do you graduate from call transcription to full QA?
Many firms have already deployed transcription. It is a useful first step: calls are captured, searchable, and available for review. But transcription alone is a visibility layer, not a quality assurance programme.
The gap between where most firms are and where the regulatory obligation points is significant:
Where most firms are now:
- Calls transcribed and stored
- QA team manually samples a small percentage of interactions (typically 2-5%)
- Compliance issues identified retrospectively, often weeks after the fact
- Coaching driven by a small, unrepresentative sample
Where process-specific AI takes you:
- Every interaction scored against policy, risk, and compliance criteria automatically
- Real-time or near-real-time flagging of high-risk conversations for immediate review
- QA coverage moves from a statistical sample to the full interaction population
- Coaching informed by patterns across all interactions, not just reviewed ones
This is a well-defined, bounded workflow with clear inputs, measurable outputs, and a direct line to regulatory compliance. It is one of the strongest early candidates for a process-specific AI proof of value in a regulated firm.
For firms considering voice agent deployments alongside QA, the considerations around FCA-compliant voice agents are worth reviewing separately.
Where should a regulated firm start?
The most common mistake at this stage is treating the post-trial decision as a platform choice. It is not. It is an architectural and governance decision first, and a technology selection second.
A practical four-step starting sequence:
- Bounded process discovery. Map the back-office workflows with the highest combination of manual effort, exception volume, and regulatory sensitivity. Do not start with the most complex process. Start with the most legible one.
- Sovereignty and governance design. Before selecting any model or vendor, define the deployment model, data boundary, logging requirements, and human oversight checkpoints for the target process. These decisions constrain your options in useful ways.
- Proof of value on a single process. Run a contained proof of value on one workflow, typically QA scoring or document classification, where inputs and outputs are well-defined and success is measurable. This builds internal confidence and a defensible evidence base.
- Sequence toward customer-facing workflows. Once back-office controls are proven, the same governance and sovereignty framework can extend to customer-facing agentic workflows. For firms evaluating that next step, the Fortay Connect CX and contact centre page covers the customer-facing dimension in more detail.
The first scaling decision after a Copilot trial should be architectural. Licence expansion can follow once the governance foundation is in place.
Ready to map your post-trial AI strategy? Download the whitepaper for a structured framework covering process discovery, sovereignty design, and sequencing for regulated financial firms.
Frequently asked questions
Why do Copilot trials plateau in regulated firms?
Copilot is designed for breadth across knowledge work. The plateau in regulated firms occurs when usage moves beyond drafting and summarising into processes that require full audit trails, explainable decisions, and data that must stay inside a defined boundary. General assistants were not built for that profile. Process-specific AI is.
Can AI work with legacy core systems that have no APIs?
Yes, though the approach depends on the system and process. Document AI, OCR/ICR, UI-layer automation, and workflow orchestration can each bridge legacy gaps without requiring a full re-platforming project. The right technique depends on process volume, exception profile, and the specific platform in question. Not every legacy environment is equally tractable, but the absence of a modern API is not an automatic barrier.
What does data sovereignty actually look like?
Data sovereignty in AI is a spectrum, not a binary. It ranges from vendor-managed cloud with contractual data controls through to fully isolated, air-gapped deployments. For regulated financial firms, the key questions are not just where data is stored, but who can access it at inference time, how model interactions are logged, and what third-party exposure exists. The right deployment model depends on process sensitivity and regulatory posture, and most firms will operate across more than one tier simultaneously.
Posts By Topics
- News (17)
- Unified Communications (17)
- Contact Centre (16)
- AI (15)
- Ring Central (13)
- Zoom (13)
- CX (12)
- Events (12)
- Avaya (7)
- GoToConnect (7)
- Contact Centre Consulting (6)
- Financial Services (6)
- Partners (6)
- Virtual Agent (6)
- Case Studies (5)
- Resources (5)
- Unified Communications Solutions (5)
- AI Meeting Assistant (2)
- AI Sales Analytics (2)
- Chatbot (2)
- Conversational Intelligence (2)
- Employee Communications (2)
- Legal (2)
- Microsoft Teams (2)
- Trends (2)
- Video (2)
- AI Companion (1)
- AI Receptionist (1)
- DialPad (1)
- Neurodiversity (1)
- Omnichannel (1)
- Sentiment Analysis (1)
- workvivo (1)